Streamlining Database Visualization: A Guide to Creating DBML ER Diagrams…
Note: We still use and love Data Factory and it’s a critical tool in our data lake toolkit. We highly recommend it for a number of tasks this particular use case just isn’t one of them
The Use Case
Over the past five years, we’ve seen a continuing shift in the Healthcare IT landscape. An increasing number of companies are operating multiple instances of single-tenant applications or expanding applications to such a scale that horizontal database-level sharding becomes essential. While there are various solutions to this complex issue—which we’ll explore in future discussions—one pressing challenge remains consistent: the fragmentation of data across disparate systems. This division hinders organizations from having a unified view of their data. Our solution addresses this challenge head-on by consolidating the data from these diverse systems into a centralized data lake, leveraging the power of Azure Databricks. This approach not only streamlines data management but also paves the way for more insightful analytics and decision-making.
The Challenge – Data Factory Per Activity Pricing
In these scenarios, we’re often dealing with transactional systems encompassing hundreds, if not thousands, of objects. To effectively unify this data, it’s not uncommon to need extraction of 40% to 80% of the entire data model, sometimes multiple times a day. Consider our initial case: about 200 objects needed extraction from 60 distinct data sources. This scale culminates in a staggering 12,000 objects requiring synchronization.
The pricing model of Data Factory, which charges per activity in addition to processing time, presented a unique challenge for us. Several preliminary activities are necessary for the copy process, such as checking state, monitoring the last sync time, logging, and error handling. After many rounds of refactoring, we managed to streamline the core extraction process down to just three activities. This equates to 3 activities multiplied by 12,000 objects per run. Divided that by 1,000, the bundle size for Data Factory activity pricing, and then multiplied by $1.50 the resulting cost is a minimum $54.00 per execution. Factoring in multiple daily executions over the course of a year, the activity costs alone soar well beyond $100,000.
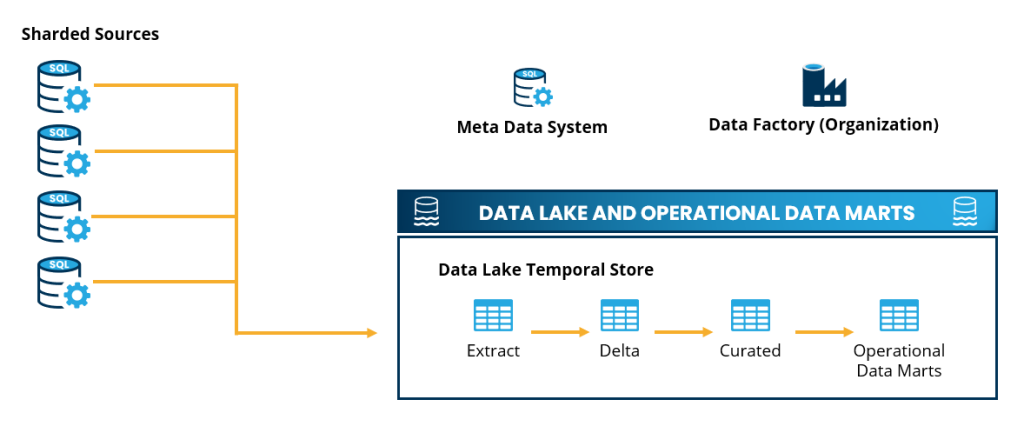
The Solution
As we sought a viable solution, our team evaluated several prominent tools, including FiveTran, Airflow, and Matillion. However, we encountered significant challenges: the balancing act between cost-effectiveness and management complexity. While both FiveTran and Matillion offered ease of management, their pricing models were prohibitive for our clientele. On the other hand, Airflow, despite its robust capabilities, presented a steep learning curve. Moreover, managing its supporting infrastructure would likely lead to long-term supportability issues.
Ultimately, we decided on a pure Azure Databricks solution, guided by a clear set of design constraints: the solution had to be a deployable notebook, entirely self-contained with no external dependencies. We chose Scala as our programming language, primarily for its ease of implementation regarding parallel processing. The final solution we architected is structured into three distinct phases: Extract, Delta, and Curated. Each phase plays a crucial role in our streamlined data processing pipeline, ensuring efficient data handling while adhering to our constraints of simplicity and cost-effectiveness.
Core Extraction Loop
Central to our solution is the Meta Data system, which plays a pivotal role in orchestrating the data extraction process. This system efficiently furnishes all the necessary meta data – encompassing details like data sources, connection strings, table names, and custom queries essential for executing the extract loop. Below is a simplified depiction of the core extract process.
Contrary to applying parallelism at the object level, we implement it at the data source level. This decision is not arbitrary; it’s a carefully considered strategy that aligns with most of our use cases. While Futures in Scala offer more control, our chosen method efficiently meets our requirements, particularly in preventing simultaneous heavy loads on the same data source. By allocating each thread to handle one table at a time per source, we ensure a balanced load, safeguarding our source systems from being overwhelmed.
Scala
// Define a function to execute data extraction
def executeExtract() {
// Retrieve data sources
val dataSources = helper.getDataSources()
// Use parallel collections for concurrent processing of data sources
dataSources.par.foreach(dataSource => {
// Get synchronization objects (tables/views) for the current data source
val syncObjects = helper.getObjects(dataSource)
// Iterate over each synchronization object
syncObjects.foreach(syncObject => {
// Perform JDBC read using Spark based on the extract query
// 'syncObject.extractQuery.get' is used to obtain the query string
val extractResultDF = spark.read.jdbc(
url = dataSource.sourceJdbcUrl,
properties = dataSource.sourceConnectionProperties,
table = s"(${syncObject.extractQuery}) as result"
)
// Write the result DataFrame to a Parquet file at the specified location
extractResultDF.write.parquet(syncObject.rawStoragePath)
})
})
}Merge Delta
In the next phase, the ‘Merge Delta’, the system dynamically integrates the newly extracted data with the existing data in the data lake. This stage is where the true ingenuity of the solution comes into play. Utilizing Azure Databricks’ powerful handling of delta merges, we’ve devised a process that not only updates and inserts new data but also maintains the historical integrity of our datasets. Each merge operation ensures only the necessary changes are applied to the data lake, thereby minimizing data redundancy and optimizing storage. The merge process takes into account various factors such as change detection, conflict resolution, and transactional consistency, ensuring that the data lake is always an accurate and up-to-date reflection of our source systems. This meticulous approach not only enhances the quality and reliability of the data but also significantly reduces the processing time and resource consumption, demonstrating the efficacy of our architecture in handling large-scale data operations with agility and accuracy.
Scala
// Define a function to execute the Delta Merge process
def executeDeltaMerge(): Unit = {
// Retrieve a list of data sources
val dataSources = helper.getDataSources()
// Process each data source in parallel for concurrent execution
dataSources.par.foreach(dataSource => {
// Retrieve synchronization objects (such as tables or views) for the current data source
val extracts = helper.getExtracts(dataSource)
// Iterate over each extract object
extracts.foreach(extract => {
// Execute SQL to create a temporary table based on the extract definition
spark.sql(extract.createTempTableScript)
// Execute the merge query to combine source and target datasets
spark.sql(extract.mergeQueryScript)
// Archive the data extract to a specified location
helper.archiveExtract(extract.archiveLocation)
})
})
}Create Curated
The final stage of our process is the creation of curated views, an essential step for consolidating and presenting the data in a user-friendly format. This ‘Curated’ phase involves structuring the data into a format that’s not only accessible but also meaningful for analysis and decision-making. To illustrate, consider the following SQL example:
SQL
CREATE VIEW Curated.SyncObject1
AS
SELECT DataSourceId, Column1, Column2, Column3, Column4, Column5
FROM DataSource1.SyncObject1
UNION ALL
SELECT DataSourceId, Column1, Column2, Column3, Column4, Column5
FROM DataSource2.SyncObject1
UNION ALL
SELECT DataSourceId, Column1, Column2, Column3, Column4, Column5
FROM DataSource3.SyncObject1
UNION ALL
SELECT DataSourceId, Column1, Column2, Column3, Column4, Column5
FROM DataSource4.SyncObject1
UNION ALL
SELECT DataSourceId, Column1, ...In this example, data from various sources is unified into a single view. Each SELECT statement corresponds to a different data source, but by using UNION ALL, we amalgamate these diverse data streams into one coherent view. This approach not only simplifies the data landscape but also enables us to maintain a clear lineage of data from its original source to its final curated form. By the end of this phase, what we have is a harmonized, comprehensive dataset ready for higher-level analytics and insights. This curated data becomes the foundation for a unified view of the data, driving efficiency and effectiveness across the organization.
The Result
Transitioning to Databricks for these key phases has brought about significant improvements, especially in terms of maintenance and cost-effectiveness. By employing Premium Job Clusters and utilizing spot instances, our extract pipeline now consistently completes within approximately 15 minutes. The cost for a full extract of all objects is remarkably economical, ranging between $2.50 and $3.50. This rate even drops further for smaller extracts. While there’s potential for further cost reduction, this current expenditure strikes an optimal balance with our performance requirements. As a result, our annual total extract cost is now anticipated to be under $5,000. Moreover, the scalability of this solution allows for easy integration of new sources or objects without a corresponding linear increase in costs. This efficiency translates into substantial savings for our customers, cutting over $100,000 annually.