An increasing number of companies are operating multiple instances of single-tenant applications or expanding applications to...
Streamlining Database Visualization: A Guide to Creating DBML ER Diagrams in Databricks Using Python
In modern data-driven environments, understanding the relationships between different database tables is crucial. Entity-Relationship Diagrams (ERDs) provide a visual representation of these relationships, making it easier for data engineers and analysts to comprehend the database structure. In this project, we tackled the challenge of dynamically generating ERDs using DBML from a Databricks environment, with features such as color-coding tables and managing multiple foreign key (FK) references.
Our goal was to automate the generation of ERDs directly from our Databricks environment. We aimed to create a solution that could:
- Dynamically extract database and table schema information.
- Generate DBML (Database Markup Language) scripts compatible with dbdiagram.io.
- Handle color-coding of tables based on database names.
- Accurately represent multiple foreign key relationships.
Databricks integration with Python and PySpark enables many use cases but automating repetitive and documentation tasks is an area it particularly excels in. Our databricks notebook is split into 4 areas:
- Retrieve database and table schema information.
- Generate DBML scripts with appropriate formatting.
- Ensure accurate handling of multiple foreign key references.
- Apply color-coding to tables for visualization.
Define Colors for Table Groups
Defining a color scheme for different databases to make the ERD more visually appealing and easier to identify different table groups or marts.
Python
table_group_colors = {
'dev.test_db': '#1f77b4', # blue
'dev.test_db2': '#ff7f0e', # orange
}Retrieve Database and Table Names
Retrieved the list of database names and, for each database, the corresponding table names.
Python
database_names = [
'dev.test_db',
'dev.test_db2'
]
tables_by_database = {}
for database_name in database_names:
try:
spark.sql(f"USE {database_name}")
tables_df = spark.sql("SHOW TABLES")
table_names = [row["tableName"] for row in tables_df.collect()]
tables_by_database[database_name] = table_names
except AnalysisException:
print(f"//Database {database_name} does not exist")Generate DBML Script
This part involved creating table definitions, handling comments, and parsing foreign key references.
Python
dbml_lines = []
for database_name, table_names in tables_by_database.items():
color = table_group_colors.get(database_name, '#000000')
# Start the table group definition
dbml_lines.append(f"tablegroup \"{database_name}\" {{")
for table_name in table_names:
dbml_lines.append(f" \"{database_name}.{table_name}\"")
dbml_lines.append("}")
for table_name in table_names:
try:
describe_query = f"DESCRIBE TABLE {database_name}.{table_name}"
describe_df = spark.sql(describe_query)
columns_list = []
for _, row in describe_df.toPandas().iterrows():
comment = row['comment'].replace("'", "") if row['comment'] else ""
columns_list.append(f" {row['col_name']} {row['data_type']} [note: '{comment}']")
foreign_keys_query = f"DESCRIBE EXTENDED {database_name}.{table_name}"
foreign_keys_df = spark.sql(foreign_keys_query)
ref_blocks = []
detailed_info = foreign_keys_df.collect()
if detailed_info:
for row in detailed_info:
if "FOREIGN KEY" in row['data_type']:
foreign_keys_info = row['data_type']
ref_table_start = foreign_keys_info.find("REFERENCES")
if ref_table_start != -1:
ref_table_info = foreign_keys_info[ref_table_start + len("REFERENCES"):].strip()
ref_table_end = ref_table_info.find("(")
if ref_table_end != -1:
ref_table_name = ref_table_info[:ref_table_end].strip().strip('`')
ref_column_start = ref_table_info.find("`", ref_table_end)
ref_column_end = ref_table_info.find("`", ref_column_start + 1)
ref_column_name = ref_table_info[ref_column_start + 1:ref_column_end]
fk_start = foreign_keys_info.find("FOREIGN KEY")
if fk_start != -1:
fk_end = foreign_keys_info.find("REFERENCES")
source_column_info = foreign_keys_info[fk_start + len("FOREIGN KEY"):fk_end].strip()
source_column_start = source_column_info.find("`")
source_column_end = source_column_info.find("`", source_column_start + 1)
source_column_name = source_column_info[source_column_start + 1:source_column_end]
ref_block = f" \"{database_name}.{table_name}\".{source_column_name} > \"{ref_table_name}\".{ref_column_name}"
ref_block = ref_block.replace("`", "")
ref_blocks.append(ref_block)
dbml_lines.append(f"Table \"{database_name}.{table_name}\" [headercolor: {color}] {{")
dbml_lines.extend(columns_list)
dbml_lines.append("}")
if ref_blocks:
for i, ref_block in enumerate(ref_blocks, start=1):
ref_name = f"{database_name.replace('.', '_')}_{table_name}_fk_{i}"
dbml_lines.append(f"Ref {ref_name} {{")
dbml_lines.append(ref_block)
dbml_lines.append("}")
except AnalysisException as e:
print(f"// Error processing table {database_name}.{table_name}: {str(e)}")
dbml_lines.append("")
Write DBML Script to a File
Finally, save the generated DBML script to our workspace for easy download\upload to dbdiagram.io.
Python
dbml_script = "\n".join(dbml_lines)
print(dbml_script)
file_path = "//Workspace/Users/someuser@yourdomain.com/dbml_script.dbml"
with open(file_path, "w+") as file:
file.write(dbml_script)Create ERD from generated DBML
With the DBML generated and written to a file in our workspace, we simply need to navigate to it, copy its contents, and finally paste into a new diagram in our ERD tool (dbdiagram.io).
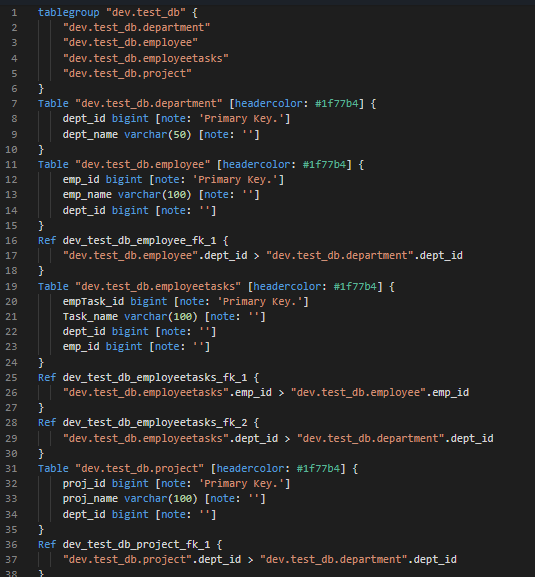
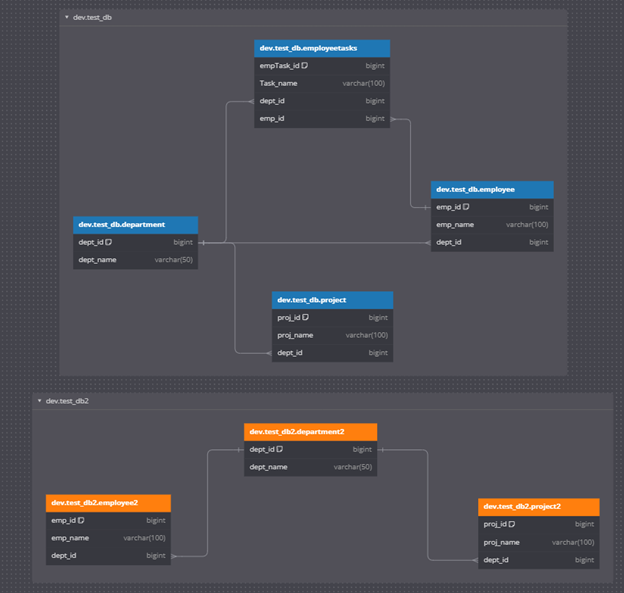
Automating the extraction of schema information and handling multiple foreign key references created a solution that simplifies the visualization of database structures. This approach saves time and also enables the ERD to stay up to date with the current database schema, providing a reliable resource for database management, analysis, and future development.